

Cory Turner has posted a piece on nprED (How learning happens) : Turnitin And The Debate Over Anti-Plagiarism Software. It hasn’t exactly gone viral, but there are at least 60 tweets and blogs which link to it, all within two days.
It is a report on a radio broadcast (a news item fronted by Turner) which is linked to from this page; also linked is a transcript of the broadcast.
First off in the broadcast, Chris Harrick, a vice-president in Turnitin’s marketing division, is explains what Turnitin is and how it works. A number of educationists then speak, some for Turnitin and some against Turnitin.
It is made clear that Turnitin does not detect plagiarism, but that it does detect matches, similarities of text. One of the problems mentioned is that Turnitin often throws up false positives, matches which would not be considered plagiarism by anyone taking the trouble to compare the student’s work against the source which allegedly matches. (No mention is made of false negatives, whereby the software fails to match material which has been copied, but that’s my aside.)
One of Turner’s interviewees, Tom Dee, said that Turnitin can be used as a hammer or as a scalpel. Some teachers hammer students, punishing them for high percentages of matches. Others use the software as a scalpel, gently helping students understand where their writing is wrong so that they learn from their mistakes.
The point is made that many students come a cropper because they do not know how to use other people’s work; their plagiarism is unintended and accidental. Tom Dee, incidentally, is co-author of a study which showed a large drop in the rate of plagiarism when students were given instruction on how to integrate other people’s work into their own and how to acknowledge that they had done this; the control group were not given this help, and their plagiarism rates were much higher. The paper states:
The results of an ex-post survey and quiz completed by participating students suggest that the treatment was effective in large part because it increased student awareness about what constitutes plagiarism and knowledge of effective writing strategies (Dee and Jacob 2010, 3).
Yes. Isn’t that called education? Teaching, preferably before the test…?
What is really interesting about Turner’s post is the two pie-charts which accompany the article.
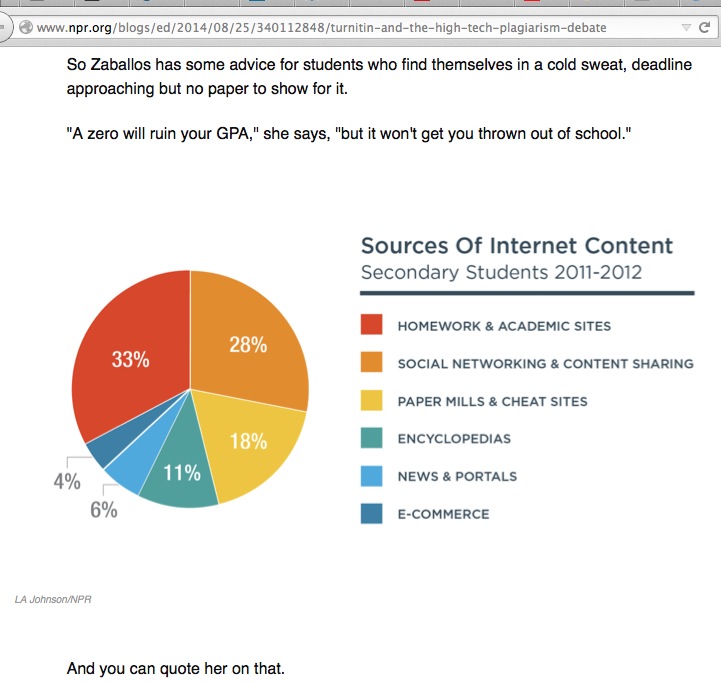
One of them shows “Sources of Internet Content: Secondary Students 2011-2012.” Most of the “Internet content” comes from Homework and Academic sites (33%) and from Social Networking and Content Sharing sites (28%). Content taken from Paper Mills and Cheat Sites accounts for 18% of Internet sources used. The graphic (see bottom left) is attributed to LA Johnson/NPR.

“Attributed to” is probably the wrong term. LA Johnson is almost certainly a designer for NPR, His name (or hers) appears under graphics on many of the articles posted on this site. But LA Johnson did not come up with the data which inform the chart. The data, the percentage rates, surely come from a Turnitin White Paper, The Sources in Student Writing – Secondary Education: Sources of Matched Content and Plagiarism in Student Writing (obtainable on application to Turnitin).
LA Johnson has changed the colours and turned the pie around, but the source is the Turnitin paper? The NPR article, however? No source given. (There is a word for this, isn’t there? It’s on the tip of my tongue…)
Even more puzzling is the second graphic.
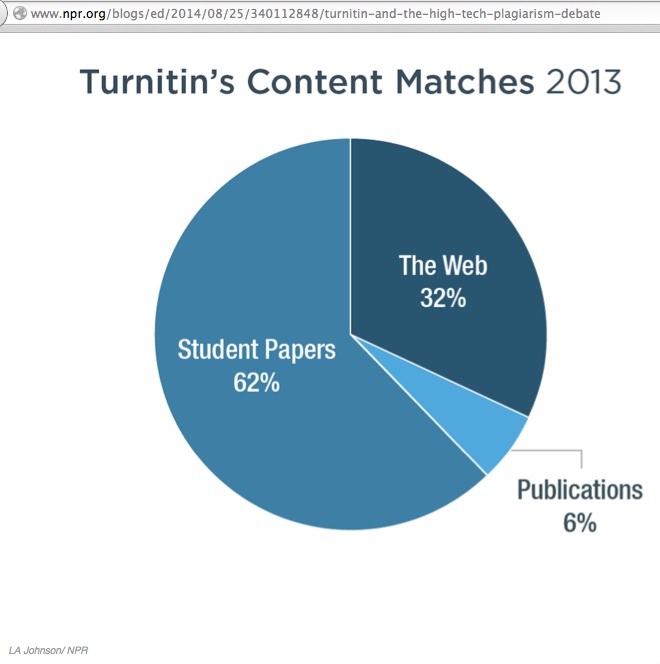
This purports to show “Turnitin’s Content Matches, 2013.” It seems that 6% of matches were from publications – whatever that means (if you, reader, know, please tell me); 32% of all matches came from “The Web” (is this different to the Internet? it is in my book); and 62% came from Student Papers.
Once again, LA Johnson/NPR gets the credit for the data, the statistics. I’m not sure how or where. I cannot find these data in any document or page on the Turnitin site (but again, if you, reader, know, please tell me). Maybe they really did originate with LA Johnson?
If these data are accurate, and who am I to say they are not, then it would seem that 38% of Turnitin’s content matches come from published sources (32% web + 6% publications), and all the rest, 62% of all content matches in 2013, was copied from papers already submitted to Turnitin and stored in the company’s collection of papers submitted by or on behalf of students.
Again, just to be clear: 62% of content matches are copied from fellow students’ papers.
It would seem – if this graph and my interpretation are accurate – that there is a huge secret network responsible for supplying student work, students copying students, collusion on a grand scale. Wow!
Actually, I find that difficult to believe. But it must be true, I found it on the Internet.
I’d feel happier though, wouldn’t you, if LA Johnson shared the source of the data?
(I have written to ask. I’ll let you know.)
Reference
Dee, T.S. and Jacob, B.A. (2010). Rational ignorance in education: A field experiment in student plagiarism. National Bureau of Economic Research. Retrieved from http://www.nber.org/papers/w15672.pdf.